UX Design · AI PROMPT WRITING | July 2023Adventuring into an AI Research Repository
Playing with the limits of AI to synthesize research findings and make them more accessible across Klarna.
Role
Senior Product Designer
Team
1 UX Researcher, 1 Engineer
The Situation
For months I had been collaborating with the UX Research team to develop new strategies for making research more easily accessible across the organization. Our beta solution was an ever-expanding monster of a spreadsheet with observations and insights input from on-going studies.
This was better than the scattered research decks we had before but search was still clunky and resulted in very low adaptation.
The Goals
Explore how Chat GPT 4.0 can be used to improve the searchability of our research repository spreadsheet.
Understand the limits and opportunities of Chat GPT 4.0 in this space (as my team mates and I were all AI-newbies) and we took on this challenge as a part of our company’s annual hackathon.
Spoiler alert we did not find a successful solution but we learned some valuable lessons about working with learning models that I want to share here in hopes that it can be helpful to other newbies.
Starting the conversation
To start we identified 2-3 of the insights from our research repository to input into Chat GPT 4.0 and asked simple questions we knew could be pulled from those insights. After some initial brainstorming on structure we decided to set up the prompt in three sections: instruction, input and question.
Note, example data used in this case study has been faked in order to protect privacy (and because it’s more fun).

First challenge: Fake news
The first problem we noticed was that model started to provide answers based on general knowledge about the topic, not necessarily pulling from our insights. We tried out the following adjustments to try and minimize this:
Changed temperature from creative to precise (1.0 to 0.1)
Added to the instruction prompt: Considering the insights provided…
Revised the question prompt: Which insight might help us answer the question {{}}?
This adjustment of the question prompt was the first switch in mindset that made me reconsider how we were talking to ChatGPT.
We knew that it would be difficult to determine the level of hallucination so having the AI basically “show us the proof” allowed us to utilize the strength of the model (parsing and identifying information) while still allowing the us to pull own own conclusions from the response; therefore minimizing the risk of fake insights.

Second challenge: Novel responses
After revising the question prompt the responses we got were technically more accurate but it was still difficult to quickly identify what insight was being referred to as we had to weed through extra paragraphs of superfluous explanation.
After playing around with the instruction prompt to request a response that was “more succinct” we then decided to rethink how we were formatting the data itself.

Following the format of our initial spreadsheet we decided to export a group of the insights/observations into CSV and adjust the prompts accordingly:
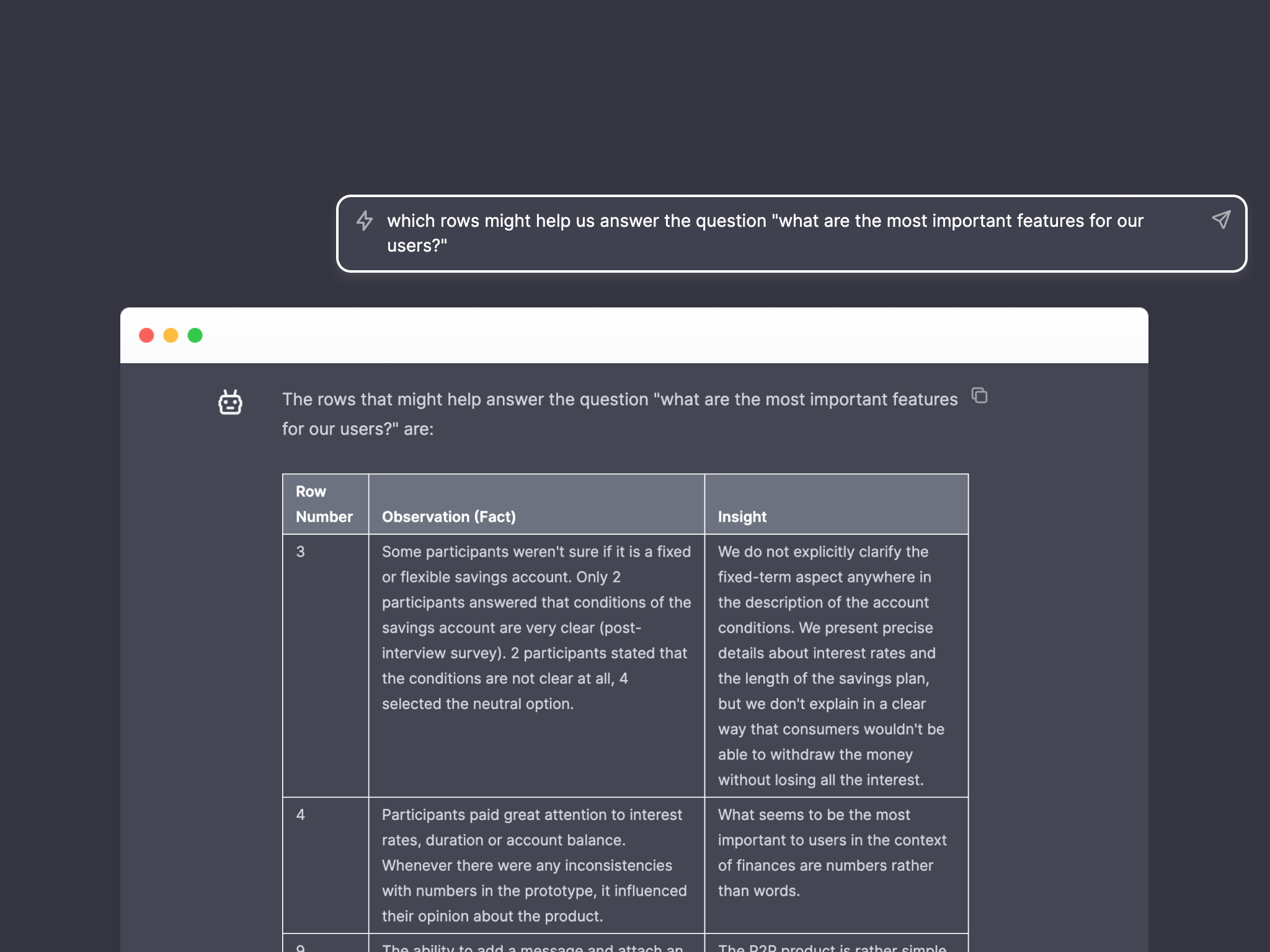
Added to the input prompt: This is a csv representation. Parse it as a table with row numbers
Revised the question prompt: “Which rows might help us answer the question {{}}?
This worked super well and made the output much more manageable but we then encountered two MORE issues:
There was no clear way to upload a document into ChatGPT.
This was “quickly” solved by writing a script that allowed us to hack the interface and upload a document but once we did that we then encountered the larger problem…There is a limit to how much data ChatGPT can process ( and our CSV had 400+ rows of data).


Third challenge: The limit does exist
Tokens are the way in which the models process information and there are limits to how much the model can process at once. Therefore we needed to figure out a way to optimize our data so that it would have the least amount of tokens without sacrificing the integrity of the data.
For example if one row of data was ~60 tokens, that meant we could only upload 133 rows. But if we could minimize it down to ~30 tokens we could upload over 260 rows.
As shown in the example there is not a totally predictable way to measure tokens so we just had to keep plugging in our rows of data and evaluating the accuracy of the summarized result.
Trial 1
This is an insight: {{}} This is an observation {{}}. Summarize these two into one paragraph, decreasing the number of characters but keep the meaning.
| Observation | Insight | Result | Evaluation |
|---|---|---|---|
Users don’t understand what they should use an airfryer for. Majority of users express that they are unsure why they should get an airfryer. They already have an oven and they use traditional pots and pans for making most meals. |
A lack of understanding as to why users need an airfryer leads them to not buying one. They need to better understand how it is different from their traditional cooking methods | Users need to comprehend the distinct advantages of the airfryer, a non-traditional kitchen appliance, to appreciate its value and utility. | The result is more succinct but summarizing doesn’t provide the same context as the observation and insight paired together. |
Trial 2
This is an insight: {{}} This is an observation {{}}. Rewrite the following statement with less characters, keep the tonality.
| Observation | Insight | Result | Evaluation |
|---|---|---|---|
Users don’t understand what they should use an airfryer for. Majority of users express that they are unsure why they should get an airfryer. They already have an oven and they use traditional pots and pans for making most meals. |
A lack of understanding as to why users need an airfryer leads them to not buying one. They need to better understand how it is different from their traditional cooking methods | Users need to grasp the airfryer’s value as a non-traditional kitchen appliance to truly desire it, given their current lack of understanding.. | Prompting the model to “rewrite” instead of “summarize” did not offer any significant change in the result. “Keeping the meaning” vs. “keep the tonality” also didn’t have much effect. |
We also encountered some issues were the model would change numerical data and rephrase things in a way that didn’t match the vocabulary we used internally (i.e. “sign-up flow” → “post-flow”). We tried to mitigate this by asking it to “Keep the tonality” but this wasn’t very successful.
Trial 3
Summarize this insight, decreasing the number of characters but keeping the meaning
| Observation | Insight | Result | Evaluation |
|---|---|---|---|
| N/A | Selecting a Design: Given the option to choose a preferred airfryer design, 90% of users selected the black model. In Sweden: One-third of users did not realize they were choosing an airfryer design, and one wanted to change it later. Half of the users preferred to review the terms and conditions for potential hidden fees before proceeding. | Given a choice of airfryer design, 9/10 users picked black. In Sweden, 2/6 didn't realize they were choosing a design, with one seeking a change later. Also, 3/6 wanted to scrutinize terms and conditions, mainly for hidden fees. | Changing percentages to fractions is not an accurate representation of the results. Need to clarify to the model to “keep all fractions” |
Key learnings
Our dataset was too big for the basic ChatGPT interface
One of the goals of our exploration was to see if we could find a lightweight AI solution that didn’t require the development of a separate platform or interface. In it’s current state (in June 2023) the lack of an upload feature and the token limit made this impossible.Summarizing insights still has a high risk of data “corruption”
In all of our iterations we never got very confident in the integrity of the summarize outputs. Some of the outputs were accurate but not 100% and with each slightly biased or misleading summary the risk of biased decision making from those insights increases.Determine your rating criteria
As were playing around with the wording we started to established some rules and agreed parameters for how to evaluate the integrity of the outputs. With more time it would have been a good exercise to further develop and refine this criteria in order to track more clearly what was or wasn’t working in the iterations.Stop asking and just be direct
We were prone to writing the prompts as “could you” or “would you” which is not necessary. Unfortunately you don’t need to be so polite with AI (but I still like to add a thank you every once in a while for good karma).